7 Questions and Answers on How to Pass the Microsoft DP-600 Exam.

The Microsoft DP-600 exam is a very popular exam, designed to help you successfully become a qualified Fabric analytics engineer associate. Therefore, many candidates will have some doubts about the exam. Here are the most popular and effective Microsoft DP-600 exam solutions.
Table of contents:
Microsoft DP-600 exam Preparation Questions 2024
Rewards for passing the Microsoft DP-600 exam
Is the Microsoft DP-600 exam difficult?
There is no doubt that it is difficult! The difficulty of the DP-600 exam is at the intermediate level. Like other Microsoft certification exams, it has a certain degree of difficulty. This is a certification exam with a distinct theme. It is mainly aimed at data analysis, so it is very fast for candidates to get started.
What is the DP-600 exam?
The Microsoft DP-600 exam is a test for those who will become certified Fabric Analytics Engineer Associates. To test your expertise in designing, creating, and deploying enterprise-wide data analytics solutions.
Skills measured
- Plan, implement, and manage a solution for data analytics
- Prepare and serve data
- Implement and manage semantic models
- Explore and analyze data
Microsoft DP-500 Exam VS Microsoft DP-600 Exam
Microsoft Fabric is an all-in-one analytics solution that covers everything from data movement to data science, transforming the role of an enterprise data analyst into that of an analytics engineer. Enterprise data analysts can now earn Fabric Analytics Engineer Associate certification by taking DP-600 and passing exam DP-600.
DP-500, DP-600, and PL-300 are role-based exams that allow you to access Microsoft Learn during the exam period. The PL-300 exam is valid for only one year and the DP-500 exam is valid until April 30, 2024. In addition, DP-600 was in the testing stage around February and is now in the mature stage in July. All candidates can take the DP-600 exam with confidence.
How to prepare for the DP-600 exam?
There are many ways to take the Microsoft DP-600 exam, such as reading books (by Daniil Maslyuk (Author), Johnny Winter (Author), Štěpán Rešl (Author)),
Self-study materials are provided through the official website, including:
- Data Engineering
- Data integration
- Data warehousing
- Real-time intelligence
- Data Science
- Business intelligence
This module introduces the Fabric platform, discusses who Fabric is for, and explores Fabric services.
Online training: udemy.com, cbtnuggets.com,learningtree.com…
And the very famous Leads4Pass IT certification material center provides DP-600 certification exam questions, free Demo online verification, PDF and VCE learning tools to facilitate online or printed learning, helping candidates easily and successfully pass the exam, with a 99.5% success rate!
Microsoft DP-600 Exam Details
Microsoft DP-600 exam details are basic information that must be known. Candidates can refer to the table below:
There were 48 “regular” questions, plus 11 questions related to two case studies. Questions vary in type: there are choice questions with a single correct answer, questions where multiple answers are correct, all the way to “fill in the blanks” and “drag answers in the right order” question types.
| Exam Code: | DP-600 |
| Exam Name: | Implementing Analytics Solutions Using Microsoft Fabric |
| Role: | Data Engineer, Data Analyst |
| Subject: | Data analytics |
| During exam | 100 minutes |
| Language: | English, Japanese, Chinese (Simplified), German, French, Spanish, Portuguese (Brazil) |
| Price: | $165 |
| Exam path: | Pearson Vue |
| Policy: | Exam Retake Policy |
Microsoft DP-600 exam Preparation Questions 2024
| Number of exam questions | Demo | IT Materials Provider | Last Update |
| 80 Q&As | 15Q&As | Leads4Pass | Jul 06, 2024 |
Question 1:
You have a Fabric tenant that contains a machine-learning model registered in a Fabric workspace. You need to use the model to generate predictions by using the predict function in a fabric notebook. Which two languages can you use to perform model scoring? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
A. T-SQL
B. DAX EC.
C. Spark SQL
D. PySpark
Correct Answer: CD
Explanation: The two languages you can use to perform model scoring in a Fabric notebook using the predict function are Spark SQL (option C) and PySpark (option D).
These are both part of the Apache Spark ecosystem and are supported for machine learning tasks in a Fabric environment. References = You can find more information about model scoring and supported languages in the context of Fabric notebooks in the official documentation on Azure Synapse Analytics.
Question 2:
You have a Fabric workspace named Workspace1 and an Azure Data Lake Storage Gen2 account named storage”!. Workspace1 contains a lakehouse named Lakehouse1.
You need to create a shortcut to storage! in Lakehouse1.
Which connection and endpoint should you specify? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
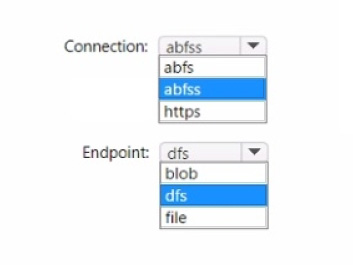
Correct Answer:
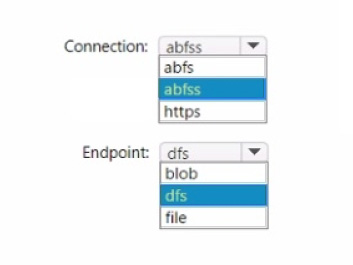
When creating a shortcut to an Azure Data Lake Storage Gen2 account in a lakehouse, you should use the abfss (Azure Blob File System Secure) connection string and the dfs (Data Lake File System) endpoint. The abyss is used for secure access to Azure Data Lake Storage, and the pdfs endpoint indicates that the Data Lake Storage Gen2 capabilities are to be used.
Question 3:
You need to provide Power Bl developers with access to the pipeline. The solution must meet the following requirements:
Ensure that the developers can deploy items to the workspaces for Development and Test.
Prevent the developers from deploying items to the workspace for Production.
Follow the principle of least privilege.
Which three levels of access should you assign to the developers? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
A. Build permission to the production semantic models
B. Admin access to the deployment pipeline
C. Viewer access to the Development and Test workspaces
D. Viewer access to the Production workspace
E. Contributor access to the Development and Test workspaces
F. Contributor access to the Production workspace
Correct Answer: BDE
Explanation: To meet the requirements, developers should have Admin access to the deployment pipeline (B), Contributor access to the Development and Test workspaces (E), and Viewer access to the Production workspace (D).
This setup ensures they can perform necessary actions in development and test environments without having the ability to affect production. References = The Power BI documentation on workspace access levels and deployment pipelines provides guidelines on assigning appropriate permissions.
Question 4:
You to need assign permissions for the data store in the AnalyticsPOC workspace. The solution must meet the security requirements.
Which additional permissions should you assign when you share the data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
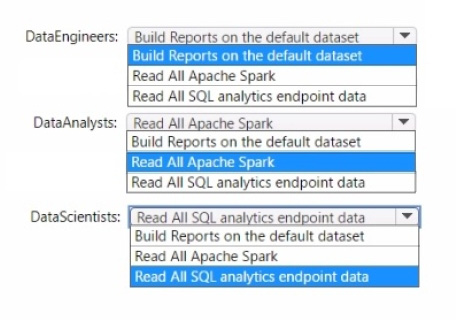
Correct Answer:
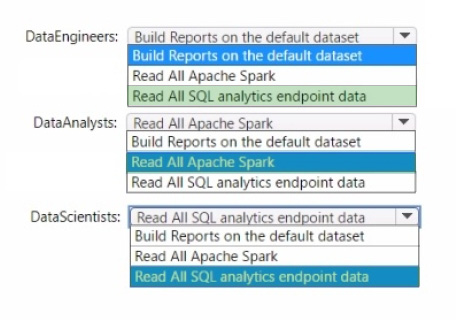
Data Engineers: Read All SQL analytics endpoint data
Data Analysts: Read All Apache Spark
Data Scientists: Read All SQL analytics endpoint data
The permissions for the data store in the AnalyticsPOC workspace should align with the principle of least privilege:
Data Engineers need read and write access but not to datasets or reports.
Data Analysts require read access specifically to the dimensional model objects and the ability to create Power BI reports.
Data Scientists need read access via Spark notebooks. These settings ensure each role has the necessary permissions to fulfill their responsibilities without exceeding their required access level.
Question 5:
You need to create a data loading pattern for a Type 1 slowly changing dimension (SCD).
Which two actions should you include in the process? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
A. Update rows when the non-key attributes have changed.
B. Insert new rows when the natural key exists in the dimension table, and the non-key attribute values have changed.
C. Update the effective end date of rows when the non-key attribute values have changed.
D. Insert new records when the natural key is a new value in the table.
Correct Answer: AD
Explanation: For a Type 1 SCD, you should include actions that update rows when non-key attributes have changed (A), and insert new records when the natural key is a new value in the table (D). A Type 1 SCD does not track historical data, so you always overwrite the old data with the new data for a given key. References = Details on Type 1 slowly changing dimension patterns can be found in data warehousing literature and Microsoft\’s official documentation.
Question 6:
You have a Fabric tenant that contains a warehouse named Warehouse1. Warehouse 1 contains a fact table named FactSales that has one billion rows. You run the following TSQL statement.
CREATE TABLE test.FactSales AS CLONE OF Dbo.FactSales;
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
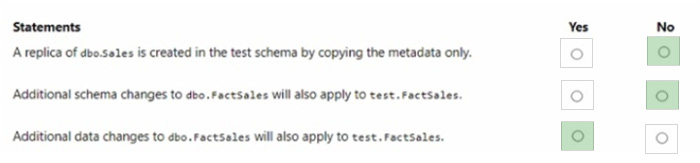
A replica of dbo.Sales is created in the test schema by copying the metadata only. – No Additional schema changes to dbo.FactSales will also apply to test.FactSales. – No Additional data changes to dbo.FactSales will also apply to test.FactSales. – Yes The CREATE TABLE AS CLONE statement creates a copy of an existing table, including its data and any associated data structures, like indexes. Therefore, the statement does not merely copy metadata; it also copies the data. However, subsequent schema changes to the original table do not automatically propagate to the cloned table. Any data changes in the original table after the clone operation will not be reflected in the clone unless explicitly updated. References = CREATE TABLE AS SELECT (CTAS) in SQL Data Warehouse
Question 7:
You have a Fabric tenant that contains a semantic model. The model contains data about retail stores.
You need to write a DAX query that will be executed by using the XMLA endpoint The query must return a table of stores that have opened since December 1, 2023.
How should you complete the DAX expression? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view
content.
NOTE: Each correct selection is worth one point.
Select and Place:

Correct Answer:
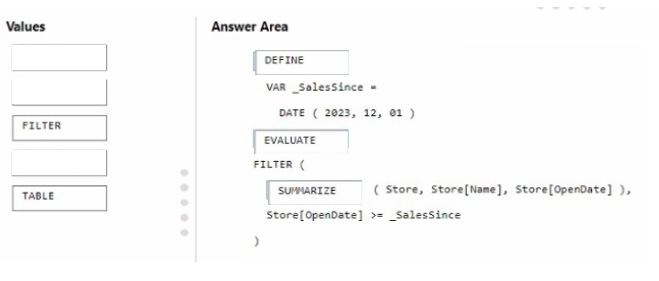
The correct order for the DAX expression would be:
DEFINE VAR _SalesSince = DATE ( 2023, 12, 01 )
EVALUATE
FILTER (
SUMMARIZE ( Store, Store[Name], Store[OpenDate] ),
Store[OpenDate] >= _SalesSince )
In this DAX query, you\’re defining a variable _SalesSince to hold the date from which you want to filter the stores. EVALUATE starts the definition of the query. The FILTER function is used to return a table that filters another table or
expression. SUMMARIZE creates a summary table for the stores, including the Store[Name] and Store[OpenDate] columns, and the filter expression Store[OpenDate] >= _SalesSince ensures only stores opened on or after December 1,
2023, are included in the results.
References =
DAX FILTER Function DAX SUMMARIZE Function
Question 8:
You have a Microsoft Power B1 report and a semantic model that uses Direct Lake mode. From Power Si Desktop, you open the Performance analyzer as shown in the following exhibit.
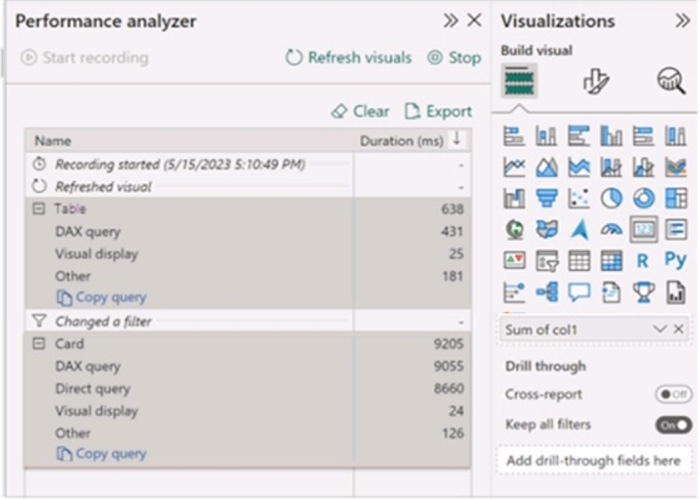
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

The Direct Lake fallback behavior is set to: DirectQueryOnly The query for the table visual is executed by using: DirectQuery
In the context of Microsoft Power BI, when using DirectQuery in Direct Lake mode, there is no caching of data and all queries are sent directly to the underlying data source.
The Performance Analyzer tool shows the time taken for different operations, and from the options provided, it indicates that DirectQuery mode is being used for the visuals, which is consistent with the Direct Lake setting. DirectQueryOnly as the fallback behavior ensures that only DirectQuery will be used without reverting to import mode.
Question 9:
You have a Fabric tenant that contains a Microsoft Power Bl report named Report 1. Report 1 includes a Python visual. Data displayed by the visual is grouped automatically and duplicate rows are NOT displayed. You need all rows to appear in the visual. What should you do?
A. Reference the columns in the Python code by index.
B. Modify the Sort Column By property for all columns.
C. Add a unique field to each row.
D. Modify the Summarize By property for all columns.
Correct Answer: C
Explanation: To ensure all rows appear in the Python visual within a Power BI report, option C, adding a unique field to each row, is the correct solution. This will prevent automatic grouping by unique values and allow for all instances of data to be represented in the visual. References = For more on Power BI Python visuals and how they handle data, please refer to the Power BI documentation.
Question 10:
You have a Fabric tenant that contains 30 CSV files in OneLake. The files are updated daily.
You create a Microsoft Power Bl semantic model named Modell that uses the CSV files as a data source. You configure incremental refresh for Model 1 and publish the model to a Premium capacity in the Fabric tenant.
When you initiate a refresh of Model1, the refresh fails after running out of resources.
What is a possible cause of the failure?
A. Query folding is occurring.
B. Only refresh complete days is selected.
C. XMLA Endpoint is set to Read Only.
D. Query folding is NOT occurring.
E. The data type of the column used to partition the data has changed.
Correct Answer: D
Explanation: A possible cause for the failure is that query folding is NOT occurring (D). Query folding helps optimize refresh by pushing down the query logic to the source system, reducing the amount of data processed and transferred, hence conserving resources. References = The Power BI documentation on incremental refresh and query folding provides detailed information on this topic.
Question 11:
You have a Fabric tenant that contains a steakhouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on the Customer.
Solution: You run the following Spark SQL statement:
REFRESH TABLE customer
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Explanation: No, the REFRESH TABLE statement does not provide information on whether maintenance tasks were performed. It only updates the metadata of a table to reflect any changes in the data files. References = The use and effects of the REFRESH TABLE command are explained in the Spark SQL documentation.
Question 12:
You are creating a dataflow in Fabric to ingest data from an Azure SQL database by using a T-SQL statement.
You need to ensure that any foldable Power Query transformation steps are processed by the Microsoft SQL Server engine.
How should you complete the code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Select and Place:

Correct Answer:

You should complete the code as follows: Table NativeQuery EnableFolding
In Power Query, using Table before the SQL statement ensures that the result of the SQL query is treated as a table. NativeQuery allows a native database query to be passed through from Power Query to the source database. The EnableFolding option ensures that any subsequent transformations that can be folded will be sent back and executed at the source database (Microsoft SQL Server engine in this case).
Question 13:
You have a Fabric tenant that contains a warehouse. The warehouse uses row-level security (RLS). You create a Direct Lake semantic model that uses the Delta tables and RLS of the warehouse. When users interact with a report built from the model, which mode will be used by the DAX queries?
A. DirectQuery
B. Dual
C. Direct Lake
D. Import
Correct Answer: A
Explanation: When users interact with a report built from a Direct Lake semantic model that uses row-level security (RLS), the DAX queries will operate in DirectQuery mode (A). This is because the model directly queries the underlying data source without importing data into Power BI. References = The Power BI documentation on DirectQuery provides detailed explanations of how RLS and DAX queries function in this mode.
Question 14:
You have a Fabric tenant that contains a warehouse.
You use a dataflow to load a new dataset from OneLake to the warehouse.
You need to add a Power Query step to identify the maximum values for the numeric columns.
Which function should you include in the step?
A. Table. MaxN
B. Table.Max
C. Table.Range
D. Table.Profile
Correct Answer: B
Explanation: The Table. The max function should be used in a Power Query step to identify the maximum values for the numeric columns. This function is designed to calculate the maximum value across each column in a table, which suits the requirement of finding maximum values for numeric columns. References = For detailed information on Power Query functions, including Table. Max, please refer to the Power Query M function reference.
Question 15:
You have a Fabric tenant that contains a steakhouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on the Customer.
Solution: You run the following Spark SQL statement:
EXPLAIN TABLE customer
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Explanation: No, the EXPLAIN TABLE statement does not identify whether maintenance tasks were performed on a table. It shows the execution plan for a query. References = The usage and output of the EXPLAIN command can be found in the Spark SQL documentation.
…
| 16th to 80th Questions | Free practice method |
| https://www.leads4pass.com/dp-600.html | PDF, VCE, PDF + VCE |
Rewards for passing the Microsoft DP-600 exam

There is no doubt that when you obtain the DP-600 Certificate (Implementing Analytics Solutions Using Microsoft Fabric), your career will be upgraded to a higher level, your income will increase, and your social class and relationships will increase, all of which are obtained through your efforts. These are the rewards you deserve.
Summarize:
The Microsoft DP-600 exam is a very meaningful certification exam. Through reasonable study and effective practice tests, you can ensure that you successfully pass the DP-600 exam.
