
We share the latest updated Microsoft DP-203 test questions and answers for free, all test questions are real cracked, guaranteed to be true and effective! You can practice the test online! Or download the latest DP-203 exam pdf.
The free exam questions are only part of what we share. If you want to get the complete Microsoft DP-203 exam questions and answers, you can get them in leads4pass.
The leads4pass DP-203 exam dumps contain VCE dumps and PDF dumps.
Microsoft DP-203 Exam “Data Engineering on Microsoft Azure” https://www.leads4pass.com/dp-203.html (Total Questions: 61 Q&A)
Get FREE Microsoft DP-203 pdf from leads4pass for free
Free share Microsoft DP-203 exam PDF from Fulldumps provided by leads4pass
https://www.fulldumps.com/wp-content/uploads/2021/05/leads4pass-Microsoft-Data-DP-203-Exam-Dumps-Braindumps-PDF-VCE.pdf
Microsoft DP-203 exam questions online practice test
QUESTION 1
HOTSPOT
Which Azure Data Factory components should you recommend using together to import the daily inventory data from
the SQL server to Azure Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
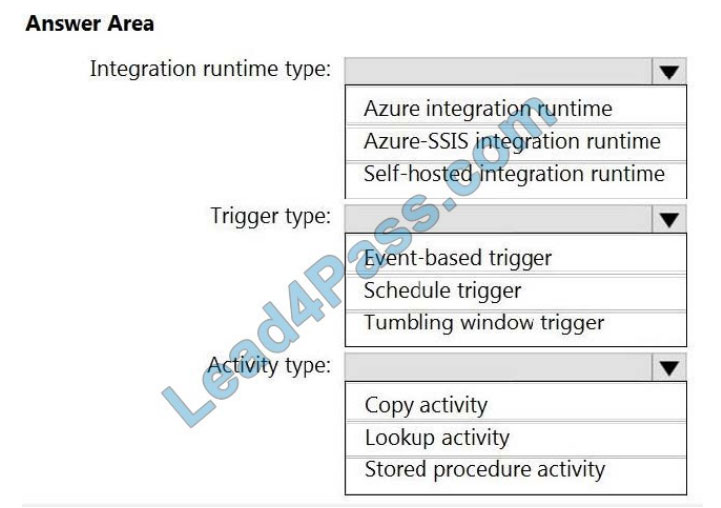
Correct Answer:
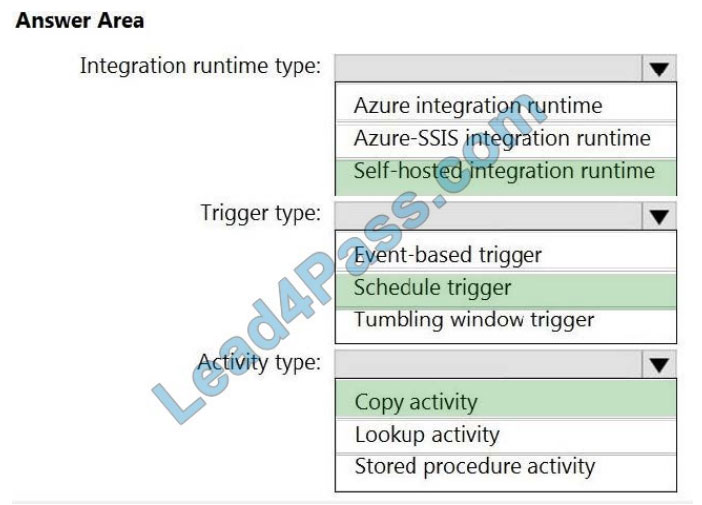
Explanation:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of running copy activity between a cloud data stores and a data store in private network.
Box 2: Schedule trigger
Schedule every 8 hours
Box 3: Copy activity
Scenario:
Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported
into Azure once every eight hours. Row modified dates are not trusted in the source table.
Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once
every eight hours. Row modified dates are not trusted in the source table.
QUESTION 2
HOTSPOT
You use Azure Data Factory to prepare data to be queried by Azure Synapse Analytics serverless SQL pools.
Files are initially ingested into an Azure Data Lake Storage Gen2 account as 10 small JSON files. Each file contains the
same data attributes and data from a subsidiary of your company.
You need to move the files to a different folder and transform the data to meet the following requirements:
Provide the fastest possible query times.
Automatically infer the schema from the underlying files.
How should you configure the Data Factory copy activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Preserver herarchy
Compared to the flat namespace on Blob storage, the hierarchical namespace greatly improves the performance of
directory management operations, which improves overall job performance.
Box 2: Parquet
Azure Data Factory parquet format is supported for Azure Data Lake Storage Gen2.
Parquet supports the schema property.
Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
https://docs.microsoft.com/en-us/azure/data-factory/format-parquet
QUESTION 3
HOTSPOT
You need to design the partitions for the product sales transactions. The solution must meet the sales transaction
dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Sales date
Scenario: Contoso requirements for data integration include:
Partition data that contains sales transaction records. Partitions must be designed to provide efficient loads by month.
Boundary values must belong to the partition on the right.
Box 2: An Azure Synapse Analytics Dedicated SQL pool
Scenario: Contoso requirements for data integration include:
Ensure that data storage costs and performance are predictable.
The size of a dedicated SQL pool (formerly SQL DW) is determined by Data Warehousing Units (DWU).
Dedicated SQL pool (formerly SQL DW) stores data in relational tables with columnar storage. This format significantly
reduces the data storage costs, and improves query performance.
Synapse analytics dedicated sql pool
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-overview-what-is
QUESTION 4
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following
three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data scientists and data engineers provide
packaged notebooks for deployment to the cluster.
All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity.
Currently, there are three data scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a High Concurrency cluster for each data scientist, a High Concurrency cluster for the data
engineers, and a Standard cluster for the jobs.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Need a High Concurrency cluster for the jobs.
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python,
R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they
provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
Reference:
https://docs.azuredatabricks.net/clusters/configure.html
QUESTION 5
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50
columns and 5 billion rows and is a heap.
Most queries against the table aggregate values from approximately 100 million rows and return only two columns.
You discover that the queries against the fact table are very slow.
Which type of index should you add to provide the fastest query times?
A. nonclustered columnstore
B. clustered columnstore
C. nonclustered
D. clustered
Correct Answer: B
Clustered columnstore indexes are one of the most efficient ways you can store your data in dedicated SQL pool.
Columnstore tables won\\’t benefit a query unless the table has more than 60 million rows.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/best-practices-dedicated-sql-pool
QUESTION 6
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following
Transact-SQL statement.
You need to alter the table to meet the following requirements:
Ensure that users can identify the current manager of employees.
Support creating an employee reporting hierarchy for your entire company.
Provide fast lookup of the managers\\’ attributes such as name and job title.
Which column should you add to the table?
A. [ManagerEmployeeID] [int] NULL
B. [ManagerEmployeeID] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
Correct Answer: A
Use the same definition as the EmployeeID column.
Reference: https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
QUESTION 7
HOTSPOT
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database
in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
Existing data must be loaded.
Data must be loaded every 30 minutes.
Late-arriving data of up to two minutes must he included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
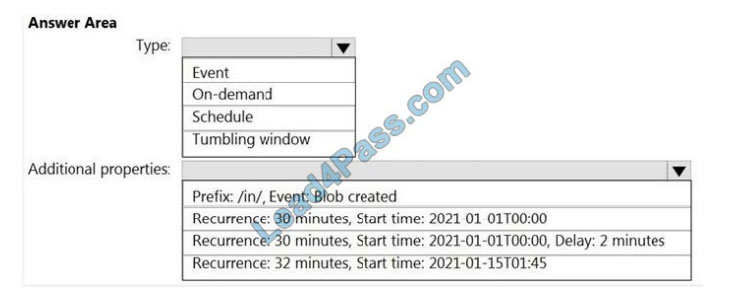
Correct Answer:
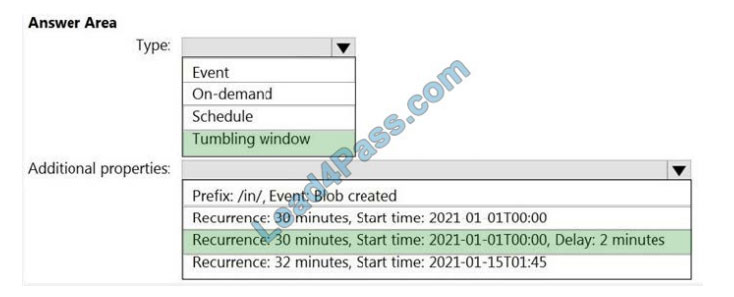
Box 1: Tumbling window
To be able to use the Delay parameter we select Tumbling window.
Box 2:
Recurrence: 30 minutes, not 32 minutes
Delay: 2 minutes.
The amount of time to delay the start of data processing for the window. The pipeline run is started after the expected
execution time plus the amount of delay. The delay defines how long the trigger waits past the due time before
triggering a
new run. The delay doesn\\’t alter the window startTime.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-tumbling-window-trigger
QUESTION 8
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that data in the pool is encrypted at rest. The solution must NOT require modifying applications that
query the data.
What should you do?
A. Enable encryption at rest for the Azure Data Lake Storage Gen2 account.
B. Enable Transparent Data Encryption (TDE) for the pool.
C. Use a customer-managed key to enable double encryption for the Azure Synapse workspace.
D. Create an Azure key vault in the Azure subscription grant access to the pool.
Correct Answer: B
Transparent Data Encryption (TDE) helps protect against the threat of malicious activity by encrypting and decrypting
your data at rest. When you encrypt your database, associated backups and transaction log files are encrypted without
requiring any changes to your applications. TDE encrypts the storage of an entire database by using a symmetric key
called the database encryption key.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-overviewmanage-security
QUESTION 9
You need to implement the surrogate key for the retail store table. The solution must meet the sales transaction dataset
requirements. What should you create?
A. a table that has an IDENTITY property
B. a system-versioned temporal table
C. a user-defined SEQUENCE object
D. a table that has a FOREIGN KEY constraint
Correct Answer: A
Scenario: Implement a surrogate key to account for changes to the retail store addresses.
A surrogate key on a table is a column with a unique identifier for each row. The key is not generated from the table
data. Data modelers like to create surrogate keys on their tables when they design data warehouse models. You can
use the IDENTITY property to achieve this goal simply and effectively without affecting load performance.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tablesidentity
QUESTION 10
HOTSPOT
You are creating dimensions for a data warehouse in an Azure Synapse Analytics dedicated SQL pool.
You create a table by using the Transact-SQL statement shown in the following exhibit.
Use the drop-down menus to select the answer choice that completes each statement based on the information
presented in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:
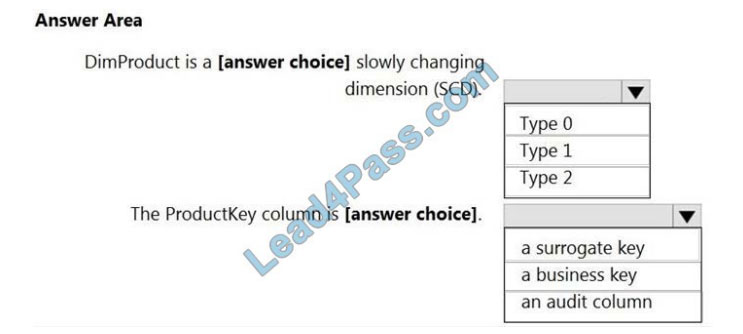
Correct Answer:
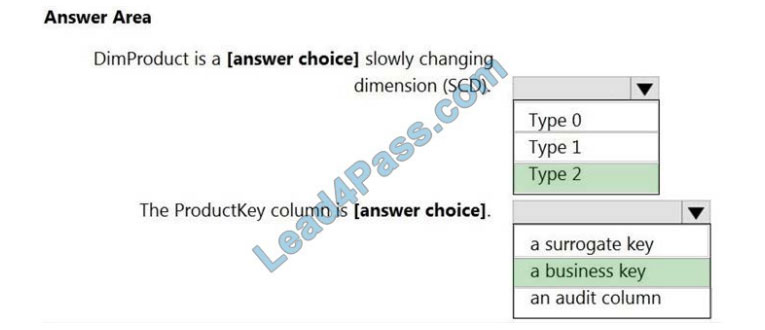
Box 1: Type 2
A Type 2 SCD supports versioning of dimension members. Often the source system doesn\\’t store versions, so the
data warehouse load process detects and manages changes in a dimension table. In this case, the dimension table
must use
a surrogate key to provide a unique reference to a version of the dimension member. It also includes columns that
define the date range validity of the version (for example, StartDate and EndDate) and possibly a flag column (for
example,
IsCurrent) to easily filter by current dimension members.
Incorrect Answers:
A Type 1 SCD always reflects the latest values, and when changes in source data are detected, the dimension table
data is overwritten.
Box 2: a business key
A business key or natural key is an index which identifies uniqueness of a row based on columns that exist naturally in a
table according to business rules. For example business keys are customer code in a customer table, composite of
sales
order header number and sales order item line number within a sales order details table.
Reference:
https://docs.microsoft.com/en-us/learn/modules/populate-slowly-changing-dimensions-azure-synapse-analyticspipelines/3-choose-between-dimension-types
QUESTION 11
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters. The solution must meet the following
requirements:
Automatically scale down workers when the cluster is underutilized for three minutes.
Minimize the time it takes to scale to the maximum number of workers.
Minimize costs.
What should you do first?
A. Enable container services for workspace1.
B. Upgrade workspace1 to the Premium pricing tier.
C. Set Cluster Mode to High Concurrency.
D. Create a cluster policy in workspace1.
Correct Answer: B
For clusters running Databricks Runtime 6.4 and above, optimized autoscaling is used by all-purpose clusters in the
Premium plan Optimized autoscaling:
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds.
The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster
makes down-scaling decisions. Increasing the value causes a cluster to scale down more slowly. The maximum value
is
600.
Note: Standard autoscaling
Starts with adding 8 nodes. Thereafter, scales up exponentially, but can take many steps to reach the max. You can
customize the first step by setting the spark.databricks.autoscaling.standardFirstStepUp Spark configuration property.
Scales down only when the cluster is completely idle and it has been underutilized for the last 10 minutes.
Scales down exponentially, starting with 1 node.
Reference:
https://docs.databricks.com/clusters/configure.html
QUESTION 12
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types
of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three
columns named username, comment, and date.
The data flow already contains the following:
A source transformation.
A Derived Column transformation to set the appropriate types of data.
A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
All valid rows must be written to the destination table.
Truncation errors in the comment column must be avoided proactively.
Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob
storage.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. To the data flow, add a sink transformation to write the rows to a file in blob storage.
B. To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
C. To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
D. Add a select transformation to select only the rows that will cause truncation errors.
Correct Answer: AB
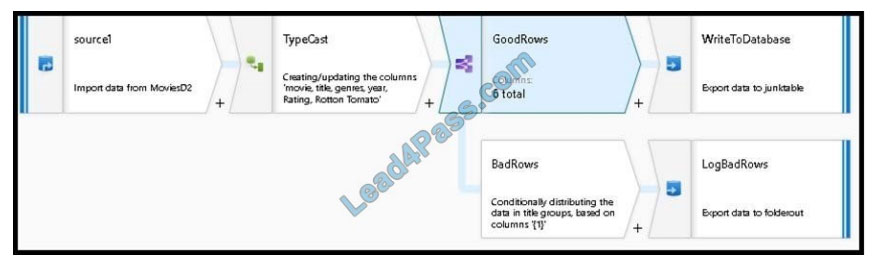
B: Example:
1.
This conditional split transformation defines the maximum length of “title” to be five. Any row that is less than or equal to
five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
2.
This conditional split transformation defines the maximum length of “title” to be five. Any row that is less than or equal to
five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.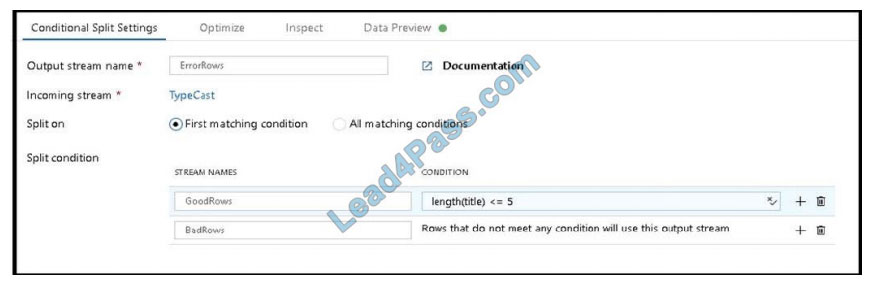
A:
3.
Now we need to log the rows that failed. Add a sink transformation to the BadRows stream for logging. Here, we\\’ll
“auto-map” all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file
output to a single file in Blob Storage. We\\’ll call the log file “badrows.csv”.
4.
The completed data flow is shown below. We are now able to split off error rows to avoid the SQL truncation errors and
put those entries into a log file. Meanwhile, successful rows can continue to write to our target database.
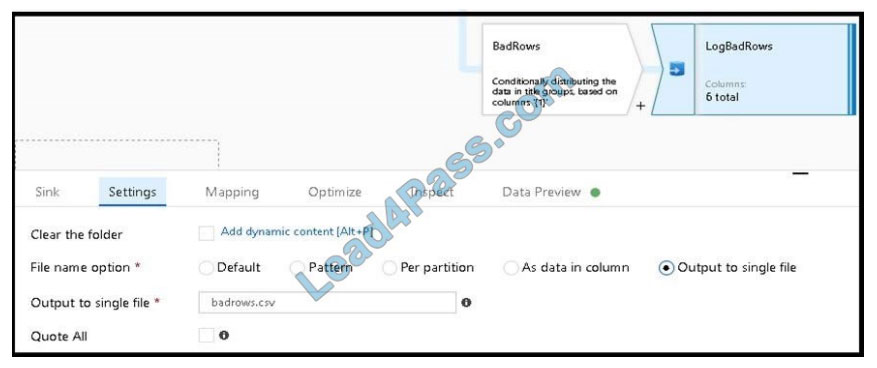
Reference: https://docs.microsoft.com/en-us/azure/data-factory/how-to-data-flow-error-rows
QUESTION 13
HOTSPOT
You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a
webpage.
The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has
a type of either \\’start\\’ or \\’end\\’.
You need to calculate the duration between start and end events.
How should you complete the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: DATEDIFF
DATEDIFF function returns the count (as a signed integer value) of the specified datepart boundaries crossed between
the specified startdate and enddate.
Syntax: DATEDIFF ( datepart , startdate, enddate )
Box 2: LAST
The LAST function can be used to retrieve the last event within a specific condition. In this example, the condition is an
event of type Start, partitioning the search by PARTITION BY user and feature. This way, every user and feature is
treated independently when searching for the Start event. LIMIT DURATION limits the search back in time to 1 hour
between the End and Start events.
Example:
SELECT [user], feature, DATEDIFF( second, LAST(Time) OVER (PARTITION BY [user], feature LIMIT
DURATION(hour, 1) WHEN Event = \\’start\\’), Time) as duration
FROM input TIMESTAMP BY Time
WHERE Event = \\’end\\’
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query-patterns
Thank you for reading! I have told you how to successfully pass the Microsoft DP-203 exam.
You can choose: https://www.leads4pass.com/dp-203.html to directly enter the DP-203 Exam dumps channel! Get the key to successfully pass the exam!
Wish you happiness!
Get free Microsoft DP-203 exam PDF online: https://www.fulldumps.com/wp-content/uploads/2021/05/leads4pass-Microsoft-Data-DP-203-Exam-Dumps-Braindumps-PDF-VCE.pdf
